クラスター分析は異なる性質が混ざった多数の個体を、個体間の類似度に基づいて似たものの集まり(クラスター)を作るための手法。判別分析ではどの群に属するかがあらかじめわかっているデータに基づいて判別関数(判別方法)を構成したのに対し、クラスター分析では分類のための外的な基準は与えられていない*1。クラスター分析は、階層型分析法と非階層型分類法に大別できる。階層型分類法は、最も似ている組み合わせから順番にクラスターを形成する。途中過程が階層のように表せるため、アウトプットとして樹形図(デンドログラム)を描くことができる。一方、非階層分類法は階層的な構造を持たない。あらかじめクラスターの数を決め、決めた数にデータを分割する方法。
個体間の類似度
次元の変数
について観察された2個体のデータを
とする。個体Aと個体Bの類似度を測る尺度として次のような距離が用いられる。
L1距離
コサイン類似度
コサイン類似度とは、n次元ベクトルの類似性を表す値でありcosθを用いる。距離という尺度を用いず、ベクトル間の方向によって類似性を定義する。ベクトルの向きが一致している場合に1、直交の場合0、向きが逆ならば-1をとる。文書(文字列)や二値データの類似度を比較する際に用いる。
(1)においてとし、
はそれぞれ以下の値をとるとする。
| 1 | 1 | 0 | 1 | 1 | |
| 1 | 0 | 0 | 0 | 1 |
には1の値が4つ含まれているため
。同様に
。内積は
]が両方1の値をとる変数の数を数えればよいので
。これらを()に代入するとcos類似度は
となる。次のデータの場合も同様の計算を行うと、cos類似度は
となる。
| 1 | 1 | 0 | 1 | 0 | |
| 1 | 0 | 1 | 0 | 1 |
クラスター間の距離
クラスター間(クラスターと各個体間)の距離の定義として代表的なものは、最短距離法*2、最長距離法*3、群平均法、重心法、ウォード法等である。図1に3つのクラスターと最短距離法、最長距離法、重心法における距離のイメージを示す。は各クラスターの中心(重心)。
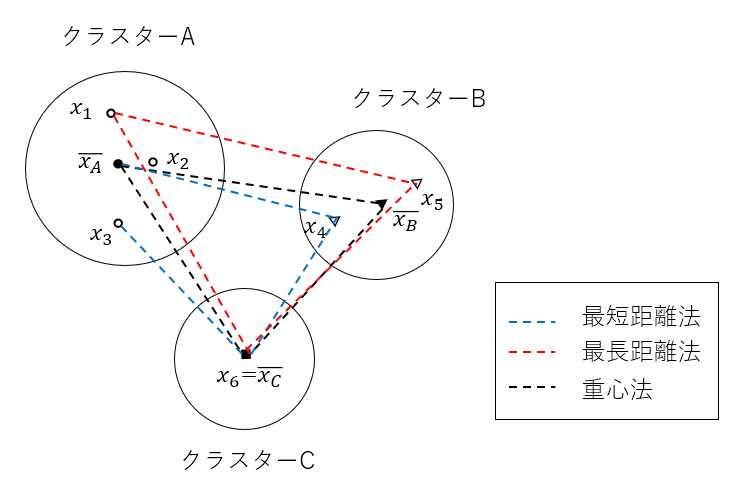
最短距離法は2つのクラスターのそれぞれの中から1個ずつ個体を選び、最も近い個体間の距離とする方法。最長距離法は2つのクラスターの中のそれぞれの中から1個ずつ個体を選び、最も離れた個体間の距離とする方法。群平均法は2つのクラスターに含まれる任意の個体間の距離の平均値を距離とする方法。重心法はクラスターの重心間の距離とする方法。重心法と同様、メディアン法においても重心間の距離を用いるが、融合した(新たに形成した)クラスターの重心の求め方に違いがある。重心法では融合したクラスターの重心をデータ数で重みを付けるのに対し、メディアン法では重心を中点とする。これにはクラスター間で含まれるデータ数に大きな差があるとき、大きいクラスターに引き込まれるのを防ぐ効果がある。
クラスター間距離として、最短距離法、最長距離法、群平均法を用いる場合は、個体間距離として(2)-(7)すべての距離を用いることができる。しかし重心法、メディアン法、ウォード法を用いる場合、個体間の距離はユークリッド距離に限られる。
クラスターの形成プロセス
クラスタリングの対象とする次元
個のデータを用意し、データに含まれる個体
間の類似度を測る距離
を定義する。
を第
成分にもつ
の正方行列を
とする。
は距離行列と呼ばれ、対角成分は0、
であるため対称行列である。距離行列からもっとも距離が近いデータの組を探し、それらを1つのクラスターにまとめる。ここで得られた最も近い距離は樹形図の1つ目の段差の高さとなり、融合の水準や融合距離と呼ばれる。先ほど形成されたクラスターと残りの個体との距離を定義し、行列数の減った新たな距離行列を作成する。先ほどと同様に最も近い組み合わせ(クラスターと個体間、または個体間)を見つけ、新たなクラスターを形成する。これを繰り返しすべてのデータを1つのクラスターにすれば分析は終了。
例として5人の生徒の数学と英語のテスト結果を用いて、階層型クラスター分析を行う。生徒(個体)間の距離はユークリッド距離、クラスター間の距離は最短距離法を用いる。

個体間の距離行列は図2のようになる。この場合生徒4と生徒5の距離が最も近いため、この組み合わせで新たなクラスターを形成する。生徒4と生徒5の距離1.4は第一ステップにおける樹形図の高さとなる。

次に距離が近い生徒1と生徒2を1つのクラスターにまとめ、残りのクラスター(個体)との距離行列を作成する。

生徒1,2と生徒3との距離が最も近いため、ここでさらにクラスターを形成する。最後に生徒1,2,3と生徒4,5のクラスター間の距離が求まり、樹形図が完成する。


図2の樹形図でクラスターの形成過程を確認すると、融合の水準(融合の距離)は1.4、2.0、2.2、2.8と単調に増加している。この性質を融合距離の単調性という。重心法やメディアン法では必ずしもこの性質を有さない。
ウォード法
ウォード法では個体間の距離をユークリッド距離とする。クラスターA、B間の距離(融合の距離)を(A,Bを融合したクラスターの偏差平方和)-{(Aの偏差平方和) + (Bの偏差平方和)}と定義する。ウォード法では起こりうるすべてのクラスターの偏差平方和を調べ、その増加が最小になるようにクラスターを形成する。クラスター形成によって生じる全偏差平方和の増加分が最小になる組み合わせを求める。

図2のクラスターA,B,Cにおける偏差平方和を計算すると、
このとき全偏差平方和は*5。クラスターA,Bを融合したとき、平均と偏差平方和は
A,Bの距離は
結合後の全偏差平方和は
A,Bの融合による全偏差平方和の増加分は
B,C、C,Aの組み合わせについても同様に距離(全偏差平方和の増加分)を計算し、それが最小となる組み合わせで新たなクラスターを形成する。
