分割法の考え方
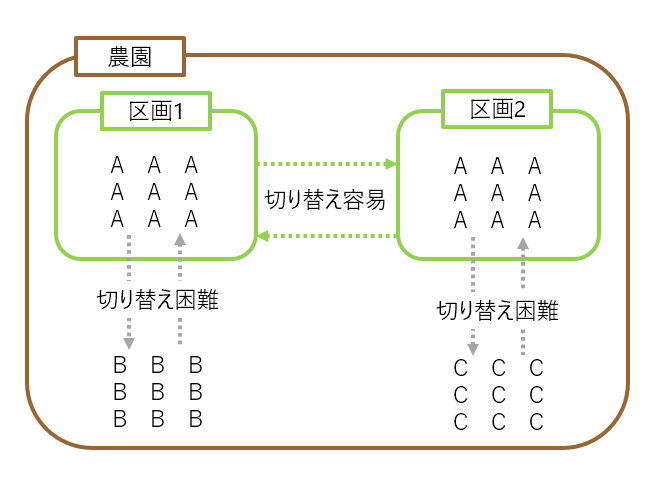
あるコーヒー農園で次のような実験を行う。3つの品種(A,B,C)と2つの区画それぞれでコーヒーを栽培し、コーヒーの収穫量を比較する。3つの品種(A.B,C)を1次因子、と2つの区画を2次因子とする。収穫の数(繰り返しの数)を2回とすると、3品種(1次因子)×2区画(1次因子)×2回繰り返しの合計12回の実験を行うことになる。しかし品種の切り替えには多大な費用と労力がかかるため容易ではない。このような場合、まず品種の実験順序を決め、次に区画の割り当てを決める。実験を容易に行うため、因子の水準の変更回数を少なくするのが分割法の考え方。
分割法では1次誤差と2次誤差の2つの誤差を考える。1次誤差が品種(A,B,C)ごとに生じる誤差、2次誤差が品種(A,B,C)と区画の相互作用によって生じる誤差である。
1次因子の繰り返しの方法には完全無作為法と乱塊法がある。
完全無作為法による1次因子の繰り返し
1次因子(A,B,Cの3つの品種)、2次因子(2つの区画)とし、繰り返し数を2回とする。1次因子(品種)の繰り返しを完全無作為法で行う。この場合1次因子(品種)の切り替え回数は5回で済む。

データの構造式は以下のように表せる。
はコーヒーの収穫量であり、品種
、区画
、繰り返しの数
である。
と
はそれぞれ1次誤差、2次誤差である。このままだと誤差が二つあり計算が困難であるため、反復の効果
を1つの水準と見なし、(1)を繰り返しのない3元配置モデルとして表すことができる。1次誤差
を
と
の交互作用、2次誤差
を
と
の交互作用だと考えると、(1)は
と表すことができる。
ここでは、
である。
乱塊法による1次因子の繰り返し
同じく1次因子(A,B,Cの3つの品種)、2次因子(2つの区画)とし、繰り返し数を2回の実験を考える。ここでは1次因子(品種)の繰り返しを乱塊法で行う。

繰り返しの回数を1つの因子としてデータの構造式に加える。
(1)と同じく繰り返しのない3元配置モデルだと考えると、(3)は
と表すことができる。ここでは、
である。
分割法の検定精度
分散分析の精度は、誤差分散が小さい方がよい。つまり誤差分散の自由度が大きい方がよい。以下のようなデータ構造式を持つ2因子実験の乱塊法の場合、
誤差分散の自由度はとなる。
他方、分割法において一次因子の繰り返しを乱塊法で行う場合、
一次誤差の自由度は、
二次誤差の自由度はとなる。
いずれにせよ2因子実験の乱塊法における自由度が最も大きい。ただし分割法の場合でも2次誤差の自由度は2因子実験の乱塊法の自由度と同じオーダーであるのに対し、1次誤差の自由度はオーダーが1つ小さい。すなわち1次因子についての検定の精度は悪く、2次因子および1次因子と2次因子の交互作用については検定の精度はよいことが分かる。したがって1次因子の影響はどうでもよく、2次因子および1次因子と2次因子の交互作用について関心がある場合は分割法を用いる。